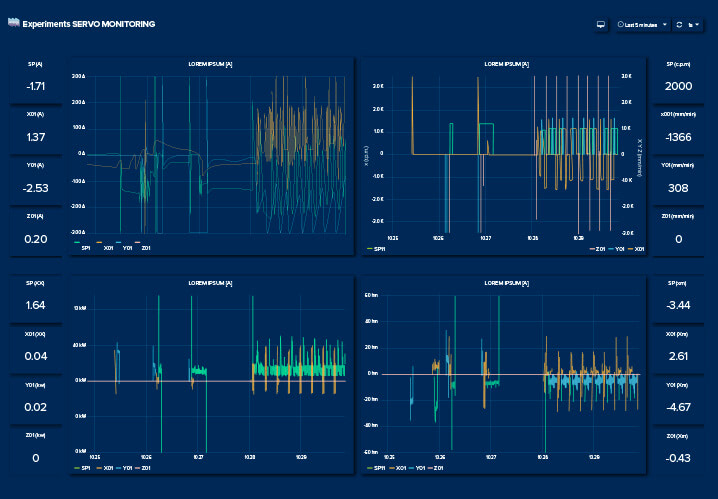

Data Acquisition
We receive the data from the sensors associated with the processes, being it our own (accelerometers, energy probes,high speed cameras), or already existing (asset’s PLC, CNC systems and other types of industrial data source). We have two differential characteristics: we work with a long range of sampling frequencies from 3 Hz up to 20 kHz (equivalent to one sample every 50 microseconds), and with a precision of 0.05 microseconds; and we can use desynchronized data: the data fusion from both sensors and systems, usually asynchronous.
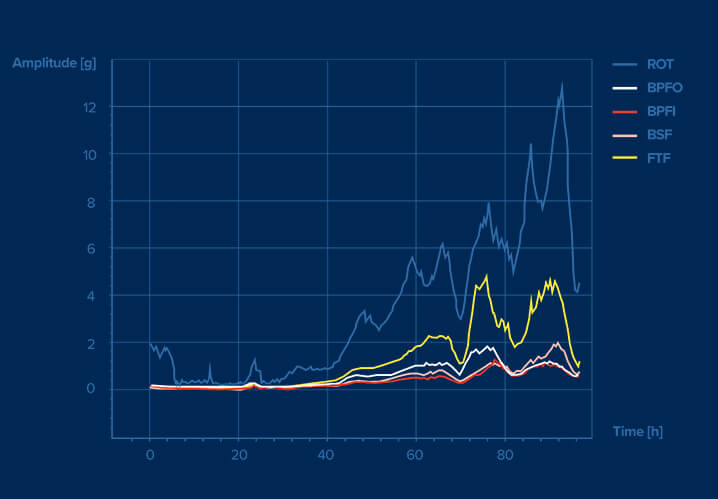

Preprocessing
We preprocess the data in continuous time, merging from different domains and sampling times, and performing different transforms and filters (linear and non linear) of them. We also run sanity checks, cleaning atypical data values. Our differentiation at this level is that we run variable selection Machine Learning based algorithms, helping us to select the most relevant variables at the time of the measurement, allowing you to work only with the necessary data. This ensures performance improvement in terms of accuracy, reliability, false positive rates, and response times, as well as reducing the needs for compute power and post analysis communication infrastructure.


Transportation and storage
We are able to store the data on the device itself, but we also send it to another node to complete local analytics. The AI module integrates into IT platforms sending data to public or private storage platforms (cloud or in premise) depending on the solution needs. The most important difference with respect to other approaches is that thanks to our preprocessing step, it is not necessary to neither store nor send all the data received upstream, but only that which requires subsequent treatments in other elements of the workflow, or whatever is considered necessary to provide traceability to the process.
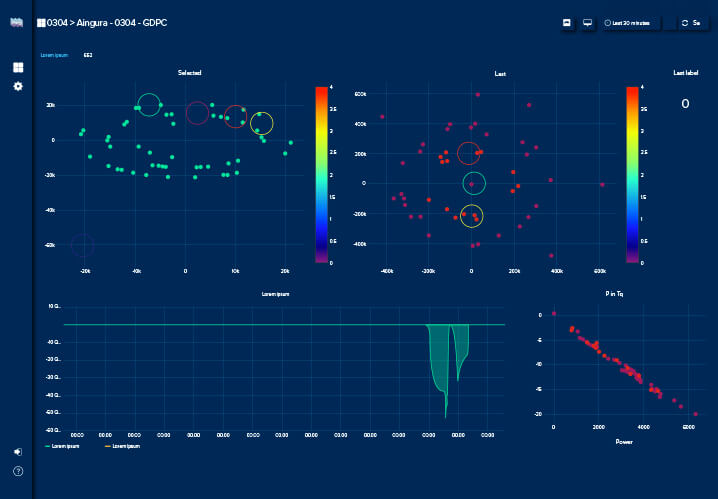

Transformation
Our core business is to design, develop and use advanced data analytics such as Artificial Intelligence (AI) algorithms deployed over Edge Computing technology to solve specific needs. Depending on the need, we work online or offline, in order to obtain actionable insights in the time required by the process. We mainly use exploratory analysis to discover behavior patterns, novelty detection to detect anomalies, to monitor degradation and estimate remaining useful life under unknown conditions. We also use supervised techniques to predict behavior if the real problem meets the requirements for this application. For what cannot be treated locally, Digital Twin models could be fed with preprocessed or partially processed data to perform long term analytics.
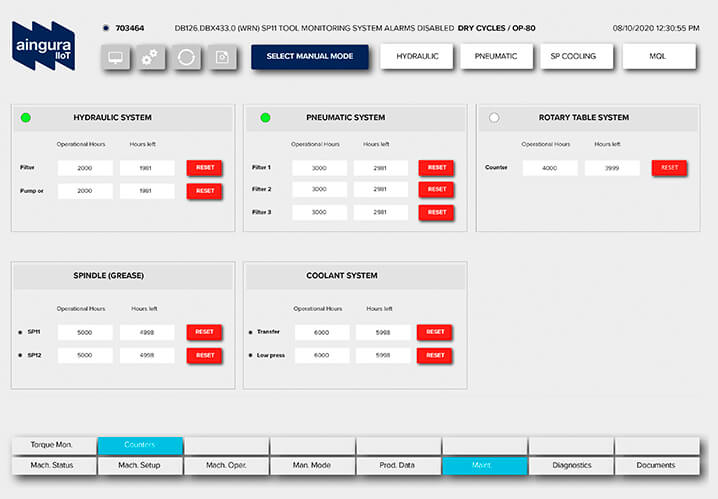

Delivery
The main objective is to provide actionable insights as knowledge bits for decision making support system for the client. Therefore, we deliver information to users based on their level of interaction with the system: from simple traffic light information, to information enriched with different KPIs for deeper or long term analytics.